Lecture 3 System Architecture
What is System Architecture
- Placement of hardware
- Processing capacity, load balancing
- Communication capacity (what machines need to communicate all the time etc.)
- Locality
- Placement of software on this hardware (mapping of services to servers)
- Partitioning - distribution of the workload
- Replication
- Caching
Architectural Patterns
Client-Server
- Sequential request/response between client and server software
- Client software uses functionality provided by server software
- Client sends request, and then waits for a response before continuing
- Scalability
- Depends on the scalability of the server - can only be scaled up so much.
- How good is the server at handling multiple requests simultaneously
- At some point there will be too many clients and we stop scaling
Splitting Functionality
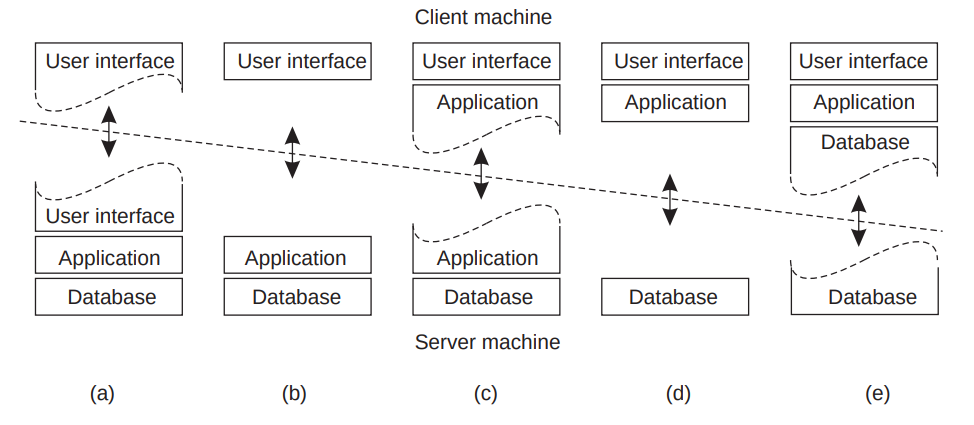
- There is always a latency cost for the communication
There are several ways of improving the scalability of the client-server model…
Vertical Distribution (Partitioning)
- Three layers of functionality: Client (UI), Application Server, Database
- Spreads out the load onto different servers
- Leads to Service-Oriented architectures
Horizontal Distribution (Replication)
- Replicate logically-equivalent applications on multiple machines
- So a request can be fulfilled by any of the replicas - can handle requests in true parallel
- Some scalability issues:
- Data changes must be propagated
- Frontend (handling and distributing incoming requests) can become overloaded
(Horizontal and Vertical distribution techniques can be combined)
Service Oriented Architecture
- System is split up into separate services (that doesn’t necessarily follow the standard partitions of UI, Application, Database)
Microservices
- Extreme vertical distribution (split down into very small application logic)
- Reusable
- Do one thing (and do it really well)
Peer-to-Peer
- Every node is both a server and a client (or servent)
- The idea is that it easily scales because whenever you add a client, you also add a server
- Challenge: How do you keep track of all peers and which ones hold what data?
- Static Structure: predefined and never changes
- Dynamic Structure: ‘Overlay Network’
- An application-specific logical network that is responsible for addressing, routing etc. It knows what communications can take place and how to route them.
- Overlay network can be structured or unstructured
- Structured Overlay Types:
- Star network: all requests go to one node
- Circular Network: each node only knows about its two neighbours
- Tree structure
- Graph structure: less organised - each servent needs to have some kind of routing functionality
- Structured overlay implementations:
- Distributed hash table - nodes have identifier and range, data has identifier
- Node is responsible for data that falls in it’s range
- Ring structure - pass to neigbouring node
- Problems: scaling (message passing to other side of ring could become slow)
- Distributed hash table - nodes have identifier and range, data has identifier
- Unstructured overlay:
- Each node has a partial view of the system (only know about some neighbours) - often exchange partial views to update info about the network in order to populate/update routing tables.
- Often get a scale-free network (often have ‘hubs’ that have lots of neighbours) when you create a random network
- Issues when nodes leave network. Hard to route (and route efficiently)
Hybrid Architectures
Combination of client-server and peer-to-peer architectures that try to overcome the problems of each
Superpeer Networks
- Some of the peers are more important than others:
- Superpeers are servers for regular peers, but superpeers are peers among themselves
- All still run the same software (some are promoted as superpeer network).
- Puts reliance on the superpeers (if they go off, need to replace/propagate changes)
- Needs a way of balancing which clients connect to which superpeers (to balance load across superpeers) - also consider locality
Collaborative Distributed Systems
- Nodes download chunks of files from many other nodes
- Have centralised file server and tracker server
- Tracker keeps track of which nodes are active and what chunks they contain
- E.g. Torrent: the torrent file indicates the chunks of file and tracker server
- To access the file, look at torrent file, then ask tracker which peer has each chunk: once you’ve asked for part of a file, you get the chunk (and this is tracked). Initially, the file is only on the file server
- Collaboration enforced by penalising selfish nodes
- Problems:
- Central Server - single point of failure (if tracker disappeared)
- Decentralised tracker implemented by distributed hash table on peers.
- Unpopular files are unlikely to have chunks on any peers
- If nobody is hosting some chunks, then you can’t get the file
- Fake nodes
- Central Server - single point of failure (if tracker disappeared)
Edge-Server Network
- Servers are placed at edge of network (e.g. at ISPs)
- Servers replicate content
- Mostly used as CDNs, application distribution
- Challenges:
- Replication Consistency
- Solution: only replicate data that’s unlikely to change
- Replication Consistency
Server Design
How do we structure the software running on individual servers?
Typical Model: Dispatcher thread that receives request and either starts or delegates request to a new/worker thread
| Model | Parallel | Blocking System Calls | Pros/Cons |
|---|---|---|---|
| Single-threaded process | No | Blocking | Blocks syscalls. Can easily see what’s goind on |
| Thread (as above) | Yes | Blocking | Server can do other work when one thread blocks, can handle simultaneous requests (faster - more scalable). More complex |
| Finite-state Machine | Yes | Non-blocking | Single-threaded. Returns to process another message when it performs syscall, and serves other requests whilst waiting for syscall to be fulfilled. |
Stateful vs. Stateless
- Stateful
- Keeps Persistent information about clients
- Improved Performance
- Expensive Crash Recovery
- Either state can be recovered, or has to restart
- Must track clients
- Stateless
- Doesn’t keep state (or soft state: limited client state)
- Can change own state without informing clients
- No cleanup after crash
- Easy to replicate - doesn’t matter which server the client connects to
- Increased communication
Clustered Servers