Lecture 8 Fault Tolerance
Dependability
We want systems to be dependent. This involves:
- Availability
- System is ready to be used immediately
- Reliability
- System can run continuously without failure
- Safety
- When a system temporarily fails, nothing catastrophic happens
- Maintainability
- How easily a failed system can be repaired
Building a dependable system is about controlling failure and faults
AWS 2011 US-East EBS Case Study
Failures
- Terminology
- Fault: the cause of an error
- Error: Part of the system state that leads to a failure (differs from it’s intended value)
- Failure: A system fails when it does not meet it’s promises / cannot provide it’s services
- Note: these can be recursive (failure can cause another fault etc.)
- Total and Partial Failure
- Total: all components in a system fail (typical in non-distributed system)
- Partial: Some components fail
- Some components affected, some may be completely unaffected
- so we can potentially recover, but dealing with partial failure is difficult
- Considered a fault for the whole distributed system
-
Fault Types
Fault Definition Transient occur once, then disappear (e.g. power outage) Intermittent occurs, vanishes, reoccurs … Permanent Persists until faulty component replaced -
Failure Types
Failure Definition Process Process proceeds incorrectly or not at all Storage “Stable” secondary storage becomes inaccessible Communication comms link or node failure - Failure Models
- Crash Failure
- Server halts, but worked correctly until it halts
- Fail-stop: Users can tell it has stopped
- Fail-resume: servers stop, then resume execution later
- Fail-Silent: Client doesn’t know the server has halted
- Omission Failure
- Server fails to respond to incoming requests
- Receive-omission: fails to receive messages
- Send-omission: fails to send messages
- Response Failure
- Server’s response is incorrect
- Value failure: value of response is wrong
- State transition failure: server deviates from correct control flow
- Timing Failure
- server’s response is outside specified time interval
- Arbitrary Failure
- server may produce arbitrary response at arbitrary time (Byzantine failure)
- To deal with these failures, system must be able to deal with failures of the worst possible kind at the worst possible time
- Crash Failure
- Detecting Failure
- Failure detector:
- Service detects process failures (answers queries about status of a proecss)
- Reliable:
- Failed (crashed)
- Unsuspected (hint - because it could fail by the time the message is recvd)
- Unreliable:
- Suspected (may have failed, or may still be alive)
- Unsuspected (hint)
- In an asynchronous systems:
- We don’t have timeout guarantees, so we can’t implement reliable failure detectors
- Timeout gives no guarantee
- Failure detector can track suspected failures
- Combine the results of multiple detectors
- Can’t distinguish between communication and process failure
- Ignore messages from suspected processes (all need to agree on what messages to ignore!)
- Turn an asynchronous system into a synchronous one (from failure point-of-view)
- We don’t have timeout guarantees, so we can’t implement reliable failure detectors
- Failure detector:
- Fault-tolerant system
- A system that can provide it’s services, even in the presence of faults
- Goal: Automatically recover from partial failure, without seriously affecting overall performance
- Techniques:
- Prevention: prevent or reduce occurrence of faults
- Quality software/hardware
- Prediction: predict the faults that can occur and deal with them
- Test for error conditions
- Error handling code
- Use error-correcting codes
- Mask: hide occurrence of fault
- Hide failures in communication and process from other processes
- Redundancy: information, time, physical
- Recovery: restore an erroneous state to an error-free state
- Prevention: prevent or reduce occurrence of faults
Reliable Communication
- Masking crash or omission failures
- Two-army Problem
- Agreement with lossy communication is impossible
- (if the last message is always lost - ack of an ack…!)
- Agreement with lossy communication is impossible
- Reliable point-to-point communication:
- TCP:
- Masks omission failure
- Doesn’t hide crash failure
- TCP:
- Possible failures (in RPC):
- Client can’t locate server
- RPC should fails - some kind of exception
- Request message to server is lost
- Server crashes after receiving request
- Reply message from server is lost
- Client crashes after sending request
- Client can’t locate server
- Reliable Group communication
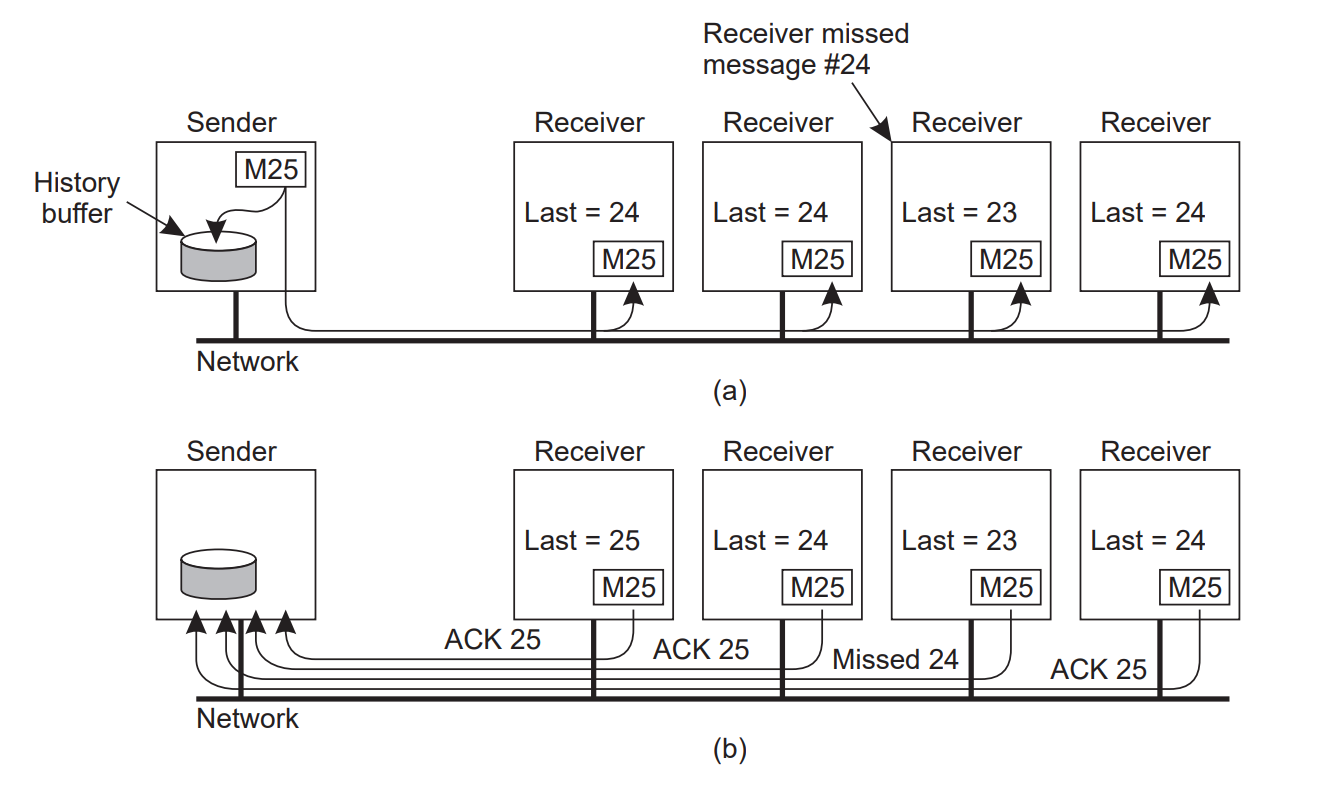
- Scalability issue: Feedback implosion - sender is swamped with feedback message
- Only use
NACK’s - Feedback supression:
NACK’s multicast to everyone (so that only one node needs to sendNACKfor re transmit)- Receivers have to be coordinated so they don’t all multicast
NACK’s at the same time - Multicasting feedback interrupts processes that have successfully received message
- Receivers have to be coordinated so they don’t all multicast
- Only use
- Hierarchical Multicast
- Efficient way of sending multicasts output to group
Process Resillience
Protecting against process failures
- Groups:
- Organise identical processes into group
- Deal with processes in a group (as single abstraction)
- Flat (collectively decide) or hierarchical (coordinator makes decision) group
Replication
- Primary-based (hierarchical group)
- Replicated-Write (flat group)
kFault Tolerance- Group can survive faults in
kcomponents, and still meet specifications - Replicas required:
k+1enough for fail silent/stop; or2k+1replicas if byzantine failure possible (since processes could ‘lie’ about their state)
- Group can survive faults in
- Each replica executes as a state machine (given some input, all correct replicas should proceed through the same set of states - deterministic).
- A ‘consensus’ (or agreement) is required (agreement on content an ordering of messages)
- Non-determinism could come into play:
- if there is an operation dependent on time!
- If systems use other distributed systems
- External factors, side effects etc.
Atomic Multicast
- A message is delivered either to all processes, or to none
- Requirement: Agreement about group membership
- “Group View”:
- View of the group that the sender has at the time of sending a message
- Each message must be uniquely associated with the group
- All processes in the group have the same view
- View Synchrony:
- A message sent by a crashing sender is either delivered to all remaining processes, or to none
- View Changes and messages are delivered in total order
- Implementations of View Synchrony:
- Stable Message: a message that has been received by all members of the group it was sent to (implemented using reliable point-to-point communication, i.e. TCP).
- If there are any unstable messages, it sends them out, and sends a
flushmessage. Once all nodes are flushed, view change occurs.
- If there are any unstable messages, it sends them out, and sends a
- Stable Message: a message that has been received by all members of the group it was sent to (implemented using reliable point-to-point communication, i.e. TCP).
Agreement
What happens when process, communication, or byzantine failure occurs during agreement algorithm?
- Variations on the Agreement Problem:
- Consensus: each process proposes a value, and all processes decide on same value
- Interactive Consistency: All processes agree on decision vector
- Byzantine Generals: Commander proposes a value, and all other processes agree on commander’s value.
- Correctness of an Agreement requires Termination, Agreement, and Validity
Byzantine General’s Problem Reliable communication, but faulty (adversarial) processes
ngenerals,mof which are traitors- If
mfaulty processes exist, then2m+1non-faulty processes are required or correct functioning- Corollary: if you have
mfaulty processes, and a total process count of2m, you cannot have a byzantine fault tolerant system 1. Need to know all others’ troop strengthg(broadcast) - Each process creates a vector of troop strength
<g1, g2, ..., gn>2. Now each process broadcasts it’s vector that it collected from troop strength broadcast 3. Each process takes the majority value for each element of the vector
- Corollary: if you have
- Simplification using Digital Signatures
- Means processes can’t lie about what someone else has said (This avoids the impossibility result)
- Can have agreement with
Consensus in an Asynchronous System
Impossible to guarantee consensus with >1 faulty process
- (Proof in notes. In practice, we can get close enough)
Consensus in Practice
Two-Phase Commit (2PC)
- Two phase commit can have failure of communication (solve with timeouts), or server failures
- Timeouts: on timeout, worker sends
GetDecisionmessage
- Timeouts: on timeout, worker sends
- Coordinator fail:
- Start a new recovery coordinator
- Learn state of protocol from workers, and finish protocol
- Coordinator and Worker Fail: Blocking 2PC
- Recovery coordinator can’t distinguish between all workers voting
Commit, and a failed worker already committed or aborted - Can’t make decision: so it blocks
- You can solve this with 3PC!
- Recovery coordinator can’t distinguish between all workers voting
Three-Phase Commit (3PC)
- Pre-commit: coordinator sends vote result to all workers, and workers acknowledge (but don’t perform action)
- Commit: coordinator tells workers to perform the voted action
Reliable, Replicated, Redundant, Fault Tolerant (RAFT) Goal: each node agrees on the same series of operations
- Log: ordered list of operations
- Leader: node responsible for deciding how to add operations to the log
- Followers: nodes that replicate the leader’s log
- Two sub-problems:
- Leader election - usually occurs when leader fails. To detect leadership fail:
- Leader sends regular heartbeat to followers
- If followers don’t see heartbeat within election timeout (random for different follower), they become candidate and start an election
- Log Replication - how to replicate the leader’s log to the followers
- Leader election - usually occurs when leader fails. To detect leadership fail:
- Term: the time during which a node is a leader
- Candidate: node who wants to become a leader
PAXOS Goal: a collection of processes chooses a single proposed value In the presence of failure
- Processor: propose value to choose
- Acceptor: accept or reject proposed values
- Learner: Any process interested in the result of a consensus
- Only proposed values can be learned
- At most one value can be learned
- If a value has been proposed then eventually a value will be learned
Algorithm:
- Propose Phase
- Propose: send proposal
<seq, value>to >= N/2 acceptors - Promise: Acceptos reply (
acceptincl last accepted value. promised = seq)
- with failure:
rejectif seq < seq of previously-accepted value
- Propose: send proposal
- Accept Phase
- Accept when >= N/2
acceptreplies are received. - Accepted: acceptors reply
- with failure:
rejectif seq < promised
- Accept when >= N/2
- Learn Phase
- Propagate value to learners when >= N/2
acceptedreplies received
- Propagate value to learners when >= N/2
Failures:
- Failures could occur in channel (loss, reorder, duplicate) or process (crash: fail-stop / fail-resume)
- Failure cases
- Acceptor fails
- Acceptor recovers/restartss
- Prpopser fails
- Multiple proposers (new proposer, proposer recovers/restarts).
- dueling proposers
- No guaranteed termination
- Heuristics to recognise the situation and back off
Recovery
Restoring an erroneous state to an error-free state
- Forward Recovery
- Correct erroneous state without moving back to a previous state
- Possible errors must be known in advance
- Backward Recovery
- Correct erroneous state by moving to a previously-correct state
- General purpose technique
- High overhead
- Error can reoccur
- Sometimes not possible to roll back
- Operation-based recovery:
- Keep a log of operations
- Restore to recovery point by reversing changes
- State-based recovery;
- Store complete state at recovery point
- Restore process sate from checkpoint
- The log or checkpoint must be recorded on stable storage
Recovery in Distributed Systems
- Failed process may have causally affected other processes
- Upon recovery of failed process, must undo the effects on these other processes
- Must roll back all affected processes
- Must roll back to a consistent global state
Checkpointing
- Pessamistic vs. Optimistic
- Pessamistic: Assume failure, optimise recovery
- Optimistic: assume infrequent failure, and minimises checkpoint overheading (i.e. less frequent)
- Independent vs. Coordinated
- Coordinated: processes synchronise to create global checkpoint
- Independent: each process takes local checkpoints
- Synchronous vs. Asynchronous
- Synchronous: distribtued computation blocked while checkpoint taken
- Asynchronous: distributed computation continues
Checkpointing Overhead
- Frequent checkopinting increases overhead
- Infrequent checkopinting increases recovery cost
- Decreasing overhead:
- Incremental checkopinting: only write changes (diff)
- Asynchronous checkopinting (copy-on-write to checkpoint while execution continues - use
fork()) - Compress checkopints: reduce IO (but more CPU time reqd.)
Consistent Checkpointing
Consistent Cut: sender must be in previous or current state, receiver must be in current state.
- Collect local checkpoints in a coordinated way (a set of local checkpoints forms a global checkpoint).
- Global checkpoint represents a consistent system state.
- Strongly-consistent checkpoint: no infomration flow during checkpoint interval
- Requires quiescent system
- Potentially long delays during blocking checkopinting
- Consistent checkpoint: all messages recorded as received must be recorded as sent
- Requires dealing with message loss
- Consistent checkpoint may not represent an actual past system state
- Taking a consistent checkpoint:
- Simple solution (high overhaed): each process checkpoints immediately after sending message
- Reducing to checkpoint after
nmessages is not guaranteed to produce a consistent checkpoint. - Need coordination during checkpointing
Synchronous Checkpointing
- Processes coordinate local checkpoint so that most recent local checkpoints are a consistent checkpoint (cut)
- Local checkpoints:
- Permanent: part of a global checkpoint
- Tentative: may become permanent, may not
- Synchronous Algorithm sinle coordinator, based on 2PC
- First Phase: Coordinator takes tentative checkpoint, then sends message to all other processes to take tentative checkpoint. If all confirm, coordinator makes it permanent
- Second Phase: coordinator informs other processes of permanent decision
- This algorithm performs redundant checkkpoints:
- it always takes strongly-consistent checkpoints
- Rollback Recovery:
- First Phase: Coordinator sends recovery message to all processes asking them to roll back.
- Each worker replies true, unless currently checkpointing.
- Coordinator decides to rollback if all replies are true
- Second Phase: coordinator sends decision to other processes, and workers initiate their own rollback.
- First Phase: Coordinator sends recovery message to all processes asking them to roll back.