Lecture 10 Distributed File Systems
Introduction to Distributed FS
- File system that is shared by distributed clients
- Communication trhoguh shared files
- Shared data remains available for a long time (persistent)
- Distributed FS is the basic layer for distributed systems and applications
- Usually in a Client/Server model
- Clients access files and directories that server provides
- Servers allow clients to perform operations on files/directories:
AddRemoveReadWrite
- Servers can provide different view of files to different clients (e.g. different access control attirbutes)
Challenges
- Transparency:
- Location
- Migration
- Replication
- Concurrency
- Flexibility:
- Servers can be added/replaced without impacting the production environment
- Support for multiple underlying file systems (abstracts away the implementation of file system on specific servers/clients).
- Dependability:
- Consistency (conflicts with replication and concurrency)
- Security (users may have different access rights on clients/network transmission)
- Fault Tolerance (server crash, availability of files)
- Performance:
- Requests may be distributed across servers
- Combining servers allow high storage capacity
- Scalability
- Handle increasing files/users
- Growth over geographic and administrative areas (how do you map users to file permissionse etc.)
- Growth of storge space
- No centralised naming service (who is responsible for naming?)
- No centralised locking, no centralised file store
Client Perspective
Ideally, the client would perceive remote files the same as local files (transparency
- Standard File Service Interface:
- File: uninterpreted sequence of bytes
- Attributes: owner, size, dates, permissions
- Protection: Access Control Lists or capabilities
- Immutable files: simplifies caching and replication
- Upload/Download model vs. Remote Access model
- Upload/Download: check out entire file, and upload changed file
- Remote Access: Client performs remote operations on file server
File Access Semantics
- UNIX Semantics:
- A
readafter awritereturns the value just written - When two
write’s follow in quick succession, the second persists - Caches are needed for performance (write-through cache expensive)
- UNIX semantics are too strong for distributed file systems (caching is too hard)
- A
- Session Semantics:
- Essentially an Upload/Download model
- Changes to an open file are only locally visible
- Wen a file is closed, changes are propagated to the server
- Merge conflicts (simultanesous writes)
- Parent/child processes can’t share file pointers if they are running on different machines
- Essentially an Upload/Download model
- Immutable file semantics:
- Only allowed to
createandreadfiles (can’twrite)write=read,create,remove/rename
- Directories can be updated (move, remove, rename etc.)
- Race condition when two clients replace the same file
- How to handle readers of a file when it’s replaced?
- Only allowed to
- Atomic Transaction semantics:
- A sequence of file manipulations is executed indivisibly
- Two transactions can never interfere
- (this is the standard semantics for databases)
- Expensive to implement
Server Perspective
- Design: What semantics are going to be used?
- Design depends on the use
- Unix Use (1980’s study):
- Most files are small
- Reading is much more common than writing
- Access is usually sequential
- Most files have short lifetime (e.g. temp files)
- File sharing is unusual (most processes only use a few files, and don’t share them)
- Distinct file classes with different properties exist (executables, documents etc)
- Is this still valid today?
- It depends on the use case
- There are many different use cases for distributed FS now
- Varying use cases:
- Big file system, many users
- High performance
- Fault tolerance
- Unix Use (1980’s study):
- Stateless vs. Stateful Servers
- Advantages of Stateless Servers
- Fault Tolerance
- No
open/closecalls needed - No server space needed for tables
- No limits on number of open files
- No problems if server or client crashes
- Advantages of Stateful Servers
- Shorter request messages
- Better performance
- Read-ahead easier
- File locking is possible
- Advantages of Stateless Servers
- Caching
- There are three locations that caching can occur:
- Main memory of the server (easy, transparent)
- Disk of the client
- Main memory of the client (process local, kernel or dedicated cache process)
- Cache consistency:
- No UNIX semantics without centralised control
- Plain write-through is too expensive
- alternatives: delay
write’s and agglomerate multiplewrites’s
- alternatives: delay
- Write-on-close, possibly with delay (file may be deleted)
- Invalid cache entries may be accessed if server is not contacted whenever a file is opened
- There are three locations that caching can occur:
- Replication
- Prevent data loss
- Protect system against down time of a single server
- Distribute workload
- Designs:
- Explicit replication: The client explicitly writes files to multiple servers (not transparent).
- Lazy file replication: Server automatically copies files to other servers after file is written.
- Group file replication:
write’s simultaneously go to a group of servers
Case Studies
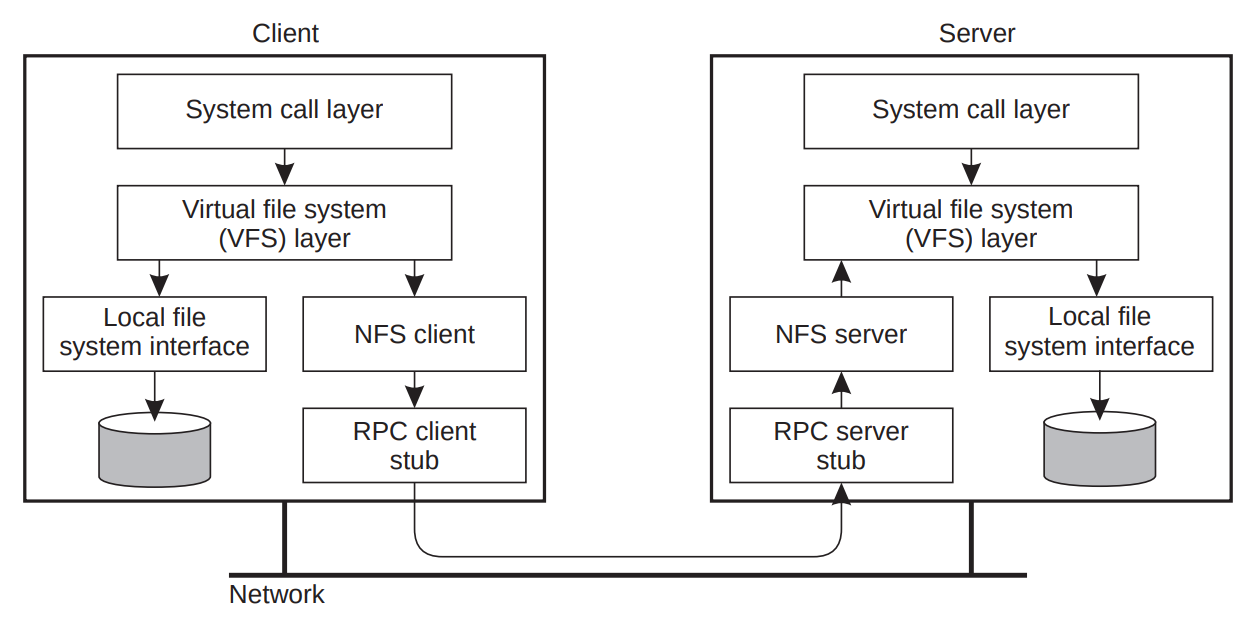
NFS
Network File System
- First developed by Sun
- Fits nicely into the Unix idea of mount points
- Does NOT implement Unix semantics
- So even though it looks like a normal file, it isn’t
- Multiple clients and servers (single machine can be client and server)
- Stateless server (this changed in version 4 to reduce network traffic etc.)
- File locking through separate server
- No replication
- Uses remote procedure calls (RPC) for communication
- Caching: local file copies
- Consistency through pollig and timestamps
- Asynchronous update of file after close
AFS
Andrew File System, successor is Coda
- Developed by CMU in 1980’s
- Idea was to develop a campus-wide file system (scalability was significant factor)
- Global name space for file system
- Unix API
- Gives Unix semantics for processes on one machine, but globally, it uses
write-on-closesemantics - Architecture:
- Client: runs user-level process (
venusAFS daemon) - Clients cache on local disk
- Group of trusted services (vice)
- Client: runs user-level process (
- Scalability:
- Servers serve entire files (clients cache files)
- Servers invalidate cached files with callback (stateful servers track all client caches)
- Clients do not validate cache (except on first use after boot)
- This means there is very little cache traffic
- Doesn’t support replication
Coda
- Supports disconnected mobile operation of clients
- Supports replication
- Disconnection operation:
- Client updates are logged in a Client Modification Log file
- On reconnection, CML is sent to the server
- Trickle reintegration tradeoff:
- Immediately reintegration of log puts heavy load on servers
- Late reintegration leads to increased risk of conflicts
- File hoarding:
- System/user can build a hoard database which is used to update frequently-used files in a hoard walk
- Conflicts automatically resolve if possible, otherwise requires manual intervention
- Servers:
- Read/write replication is organised per-volume (replicate entire volumes)
- Group file replication (mluticast remote procedural calls):
readfrom any server - Version stamps are used to recognise server with outdated files
GFS
Google File System
- Designed for commercial/R&D applications
- Aim to support 10’s of clusters, with 1000’s of nodes each,
- 300TB+ file systems, and 500Mb/s load
- Assumptions:
- Failure occurs often
- Huge files
- Large streaming
read's - Small random
read’s - Concurent appends
- Bandwidth more important than latency
- Interface:
- No common standard like POSIX.
- Provides familiar file system interface
- Operations:
createdeleteopenclosereadwritesnapshot: low-cost copy of an entire file (copy-on-write)record append: atomic append operation. Concurrent appents isolated.
- System Design
- Files split into large (64MB) chunks
- Chunks stored on chunk servers (replicated)
- GFS master manages the name space
- Clients interract with master to get chunk handle
- Clients interract with chunk servers for reads/writes
- No explicit caching
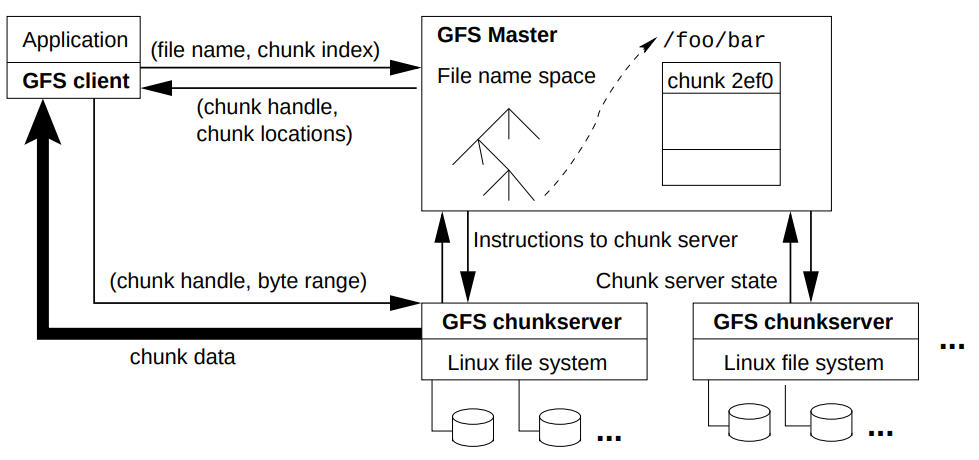
- GFS Master:
- Single point of failure
- Keeps data structures in memory
- Mutations logged to the operation log (replicated)
- Checkpoint state when log is too large (checkpoint is same form as memory - quick recovery)
- Locations of hcunks not stored at master (master periodically asks chunk servers for lists of chunks)
- Chunk Servers
- Checksum blocks of chunks
- Verify checksums before data is delivered, and of seldom-used blocks when idle
- Data Mutations (
write,record append,snapshot)- Master grants hcunk lease to a chunk replica
- Replica with chunk becomes primary
- Primary defines serial order for all mutations
- Leases typically expire after 60s (usually extended)
- If primary fails, master chooses another replica after lease expires
- Evaluating GFS (after 10 years of use)
- Single Master Problem
- Too many requests (overloading)
- Single point of failure
- Solutions:
- Tune performance
- Multiple cells
- Develop distributed masters
- File Counts
- Too much metadata for single master
- Applications changed to rely on “Big Table” instead
- File size
- Smaller than expected
- Reduced block size to 1MB
- Throughput vs Latency
- Too much latency for interactive applicatoins
- Automated master failover introduced
- Applications modified to hide latency (e.g. multi-homed model)
- Single Master Problem
Other File Systmes from Google
Chubby
- Lock service
- Simple FS
- Name service
- Synchronisation/consensus service
- Implements Paxos
- Architecture:
- Defines cells consisting of 5 replicas
- Master:
- Gets all client requests
- Master elected using paxos - given lease
write: Paxos agreement on replicasread: performed local by master
- API:
- Lock services defined as path names
- Operations:
open,close,read,write,delete,- Locks:
acquire,release` - Events:
lock acquired, file modified` etc.
- Locks:
- Simple leader election using Chubby:
- Everyone who wants to become master tries to open the same file - only one will succeed
if (open("/ls/cell/TheLeader", W)) { write(my_id); } else { wait until "/ls/cell/TheLeader" modified; leader_id = read(); }
- Everyone who wants to become master tries to open the same file - only one will succeed
Colossus
- Follow up to GFS
BigTable
- Distributed, sparse, storage map (key-value data)
- Uses Chubby for consistency
- Uses GFS/Colossus for actual storage
Megastore
- Semi-relational database (provides ACID transactions)
- Uses BigTable for storage (synchronous replication using Paxos)
- Poor write latency and throughput
Spanner
- SQL-like, structured storage
- Transactions with TrueTime (synchronous replication using Paxos)
- Optimised for low latency